Optimizing Online Sports Retail Revenue (SQL Analysis Project)
In this notebook, we play the role of a product analyst for an online sports clothing company. The company is specifically interested in how it can improve revenue. We will dive into product data such as pricing, reviews, descriptions, and ratings, as well as revenue and website traffic, to produce recommendations for its marketing and sales teams.
The postgresql database that I have set up locally, onlineretail, contains five tables, with product_id being the primary key for all of them:
info
| column | data type | description |
|---|---|---|
product_name |
varchar |
Name of the product |
product_id |
varchar |
Unique ID for product |
description |
varchar |
Description of the product |
finance
| column | data type | description |
|---|---|---|
product_id |
varchar |
Unique ID for product |
listing_price |
float |
Listing price for product |
sale_price |
float |
Price of the product when on sale |
discount |
float |
Discount, as a decimal, applied to the sale price |
revenue |
float |
Amount of revenue generated by each product, in US dollars |
reviews
| column | data type | description |
|---|---|---|
product_name |
varchar |
Name of the product |
product_id |
varchar |
Unique ID for product |
rating |
float |
Product rating, scored from 1.0 to 5.0 |
reviews |
float |
Number of reviews for the product |
traffic
| column | data type | description |
|---|---|---|
product_id |
varchar |
Unique ID for product |
last_visited |
timestamp |
Date and time the product was last viewed on the website |
brands
| column | data type | description |
|---|---|---|
product_id |
varchar |
Unique ID for product |
brand |
varchar |
Brand of the product |
%%capture
%load_ext sql
1. Counting missing values
We will be dealing with missing data as well as numeric, string, and timestamp data types to draw insights about the products in the online store. Let's start by finding out how complete the data is.
%%sql
postgresql://postgres:onlineretail@127.0.0.1/onlineretail
-- Count all columns as total_rows
-- Count the number of non-missing entries for description, listing_price, and last_visited
-- Join info, finance, and traffic
SELECT COUNT(*) AS total_rows,
COUNT(i.description) AS count_description,
COUNT(f.listing_price) AS count_listing_price,
COUNT(t.last_visited) AS count_last_visited
FROM info AS i
INNER JOIN finance AS f
ON i.product_id = f.product_id
INNER JOIN traffic AS t
ON t.product_id = f.product_id;
1 rows affected.
| total_rows | count_description | count_listing_price | count_last_visited |
|---|---|---|---|
| 3179 | 3117 | 3120 | 2928 |
2. Nike vs Adidas pricing
We can see the database contains 3,179 products in total. Of the columns we previewed, only one — last_visited — is missing more than five percent of its values. Now let's turn our attention to pricing.
How do the price points of Nike and Adidas products differ? Answering this question can help us build a picture of the company's stock range and customer market. We will run a query to produce a distribution of the listing_price and the count for each price, grouped by brand.
%%sql
-- Select the brand, listing_price as an integer, and a count of all products in finance
-- Join brands to finance on product_id
-- Aggregate results by brand and listing_price, and sort the results by listing_price in descending order
-- Filter for products with a listing_price more than zero
SELECT
b.brand,
CAST (f.listing_price AS INTEGER),
COUNT(f.product_id)
FROM brands AS b
INNER JOIN finance AS f
ON b.product_id = f.product_id
WHERE f.listing_price > 0
GROUP BY b.brand, f.listing_price
ORDER BY f.listing_price DESC
* postgresql://postgres:***@127.0.0.1/onlineretail
77 rows affected.
| brand | listing_price | count |
|---|---|---|
| Adidas | 300 | 2 |
| Adidas | 280 | 4 |
| Adidas | 240 | 5 |
| Adidas | 230 | 8 |
| Adidas | 220 | 11 |
| Adidas | 200 | 8 |
| Nike | 200 | 1 |
| Adidas | 190 | 7 |
| Nike | 190 | 2 |
| Adidas | 180 | 34 |
| Nike | 180 | 4 |
| Adidas | 170 | 27 |
| Nike | 170 | 14 |
| Adidas | 160 | 28 |
| Nike | 160 | 31 |
| Adidas | 150 | 41 |
| Nike | 150 | 6 |
| Adidas | 140 | 36 |
| Nike | 140 | 12 |
| Adidas | 130 | 96 |
| Nike | 130 | 12 |
| Adidas | 120 | 115 |
| Nike | 120 | 16 |
| Adidas | 110 | 91 |
| Nike | 110 | 17 |
| Adidas | 100 | 72 |
| Nike | 100 | 14 |
| Adidas | 96 | 2 |
| Nike | 95 | 1 |
| Adidas | 90 | 89 |
| Nike | 90 | 13 |
| Adidas | 86 | 7 |
| Adidas | 85 | 1 |
| Nike | 85 | 5 |
| Adidas | 80 | 322 |
| Nike | 80 | 16 |
| Nike | 79 | 1 |
| Adidas | 76 | 149 |
| Adidas | 75 | 1 |
| Nike | 75 | 7 |
| Adidas | 70 | 87 |
| Nike | 70 | 4 |
| Adidas | 66 | 102 |
| Nike | 65 | 1 |
| Adidas | 63 | 1 |
| Adidas | 60 | 211 |
| Nike | 60 | 2 |
| Adidas | 56 | 174 |
| Adidas | 55 | 2 |
| Adidas | 53 | 43 |
| Adidas | 50 | 183 |
| Nike | 50 | 5 |
| Adidas | 48 | 42 |
| Nike | 48 | 1 |
| Adidas | 46 | 163 |
| Adidas | 45 | 1 |
| Nike | 45 | 3 |
| Adidas | 43 | 51 |
| Adidas | 40 | 81 |
| Nike | 40 | 1 |
| Adidas | 38 | 24 |
| Adidas | 36 | 25 |
| Adidas | 33 | 24 |
| Adidas | 30 | 37 |
| Nike | 30 | 2 |
| Adidas | 28 | 38 |
| Adidas | 27 | 18 |
| Adidas | 25 | 28 |
| Adidas | 23 | 1 |
| Adidas | 20 | 8 |
| Adidas | 18 | 4 |
| Adidas | 16 | 4 |
| Adidas | 15 | 27 |
| Adidas | 13 | 27 |
| Adidas | 12 | 1 |
| Adidas | 10 | 11 |
| Adidas | 9 | 1 |
3. Labeling price ranges
It turns out there are 77 unique prices for the products in our database, which makes the output of our last query quite difficult to analyze.
Let's build on our previous query by assigning labels to different price ranges, grouping by brand and label. We will also include the total revenue for each price range and brand.
%%sql
-- Select the brand, a count of all products in the finance table, and total revenue
-- Create four labels for products based on their price range, aliasing as price_category
-- Join brands to finance on product_id
-- Group results by brand and price_category, sort by total_revenue and filter out products missing a value for brand
SELECT
b.brand,
COUNT(f.product_id),
SUM(f.revenue) as total_revenue,
CASE WHEN f.listing_price < 42 THEN 'Budget'
WHEN f.listing_price >= 42 AND f.listing_price <72 THEN 'Average'
WHEN f.listing_price >= 72 AND f.listing_price <129 THEN 'Expensive'
ELSE 'Elite' END AS price_category
FROM brands AS b
INNER JOIN finance AS f
ON b.product_id = f.product_id
WHERE b.brand IS NOT NULL
GROUP BY b.brand, price_category
ORDER BY total_revenue DESC
* postgresql://postgres:***@127.0.0.1/onlineretail
8 rows affected.
| brand | count | total_revenue | price_category |
|---|---|---|---|
| Adidas | 849 | 4626980.069999999 | Expensive |
| Adidas | 1060 | 3233661.060000001 | Average |
| Adidas | 307 | 3014316.8299999987 | Elite |
| Adidas | 359 | 651661.1200000002 | Budget |
| Nike | 357 | 595341.0199999992 | Budget |
| Nike | 82 | 128475.59000000003 | Elite |
| Nike | 90 | 71843.15000000004 | Expensive |
| Nike | 16 | 6623.5 | Average |
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import pandas as pd
from matplotlib.ticker import StrMethodFormatter, NullFormatter
sns.set_style('darkgrid')
sns.set(rc={"figure.figsize":(8, 5)})
sales = %sql SELECT b.brand, COUNT(f.product_id), SUM(f.revenue) as total_revenue, CASE WHEN f.listing_price < 42 THEN 'Budget' WHEN f.listing_price >= 42 AND f.listing_price <72 THEN 'Average' WHEN f.listing_price >= 72 AND f.listing_price <129 THEN 'Expensive' ELSE 'Elite' END AS price_category FROM brands AS b INNER JOIN finance AS f ON b.product_id = f.product_id WHERE b.brand IS NOT NULL GROUP BY b.brand, price_category ORDER BY total_revenue DESC
sales_df = sales.DataFrame()
sales_df['price_category'] = pd.Categorical(sales_df['price_category'], ["Elite", "Expensive", "Average", "Budget"])
ax = sns.barplot(y='total_revenue', x='price_category', hue='brand', data=sales_df)
ax.set_title('Sales by Price Category and Brand');
ax.yaxis.set_major_formatter(StrMethodFormatter('{x:.0f}'))
ax.yaxis.set_minor_formatter(NullFormatter())
plt.show()
* postgresql://postgres:***@127.0.0.1/onlineretail
8 rows affected.
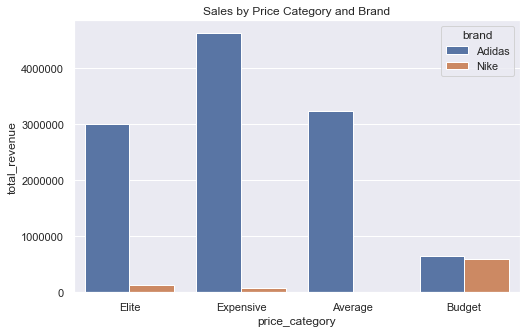
4. Average discount by brand
Interestingly, grouping products by brand and price range allows us to see that Adidas items generate more total revenue regardless of price category! Specifically, "Elite" Adidas products priced \$129 or more typically generate the highest revenue, so the company can potentially increase revenue by shifting their stock to have a larger proportion of these products!
Note we have been looking at listing_price so far. The listing_price may not be the price that the product is ultimately sold for. To understand revenue better, let's take a look at the discount, which is the percent reduction in the listing_price when the product is actually sold. We would like to know whether there is a difference in the amount of discount offered between brands, as this could be influencing revenue.
%%sql
-- Select brand and average_discount as a percentage
-- Join brands to finance on product_id
-- Aggregate by brand
-- Filter for products without missing values for brand
SELECT
b.brand,
AVG(f.discount)*100 as average_discount
FROM brands as b
INNER JOIN finance as f
ON b.product_id = f.product_id
WHERE b.brand IS NOT NULL
GROUP BY b.brand
* postgresql://postgres:***@127.0.0.1/onlineretail
2 rows affected.
| brand | average_discount |
|---|---|
| Nike | 0.0 |
| Adidas | 33.452427184465606 |
5. Correlation between revenue and reviews
Strangely, no discount is offered on Nike products! In comparison, not only do Adidas products generate the most revenue, but these products are also heavily discounted!
To improve revenue further, the company could try to reduce the amount of discount offered on Adidas products, and monitor sales volume to see if it remains stable. Alternatively, it could try offering a small discount on Nike products. This would reduce average revenue for these products, but may increase revenue overall if there is an increase in the volume of Nike products sold.
Now explore whether relationships exist between the columns in our database. We will check the strength and direction of a correlation between revenue and reviews.
%%sql
-- Calculate the correlation between reviews and revenue as review_revenue_corr
-- Join the reviews and finance tables on product_id
SELECT
corr(f.revenue, r.reviews) as review_revenue_corr
FROM reviews as r
INNER JOIN finance as f
ON r.product_id = f.product_id
* postgresql://postgres:***@127.0.0.1/onlineretail
1 rows affected.
| review_revenue_corr |
|---|
| 0.6518512283481301 |
6. Ratings and reviews by product description length
Interestingly, there is a strong positive correlation between revenue and reviews. This means, potentially, if we can get more reviews on the company's website, it may increase sales of those items with a larger number of reviews.
Perhaps the length of a product's description might influence a product's rating and reviews — if so, the company can produce content guidelines for listing products on their website and test if this influences revenue. Let's check this out!
%%sql
-- Calculate description_length
-- Convert rating to an integer and calculate average_rating
-- Join info to reviews on product_id and group the results by description_length
-- Filter for products without missing values for description, and sort results by description_length
SELECT
TRUNC(LENGTH(i.description), -2) as description_length,
ROUND(AVG(r.rating::numeric),2) as average_rating
FROM info as i
INNER JOIN reviews as r
on i.product_id = r.product_id
WHERE i.description is NOT NULL
GROUP BY description_length
ORDER BY description_length
* postgresql://postgres:***@127.0.0.1/onlineretail
7 rows affected.
| description_length | average_rating |
|---|---|
| 0 | 1.87 |
| 100 | 3.21 |
| 200 | 3.27 |
| 300 | 3.29 |
| 400 | 3.32 |
| 500 | 3.12 |
| 600 | 3.65 |
7. Reviews by month and brand
Unfortunately, there doesn't appear to be a clear pattern between the length of a product's description and its rating.
As we know a correlation exists between reviews and revenue, one approach the company could take is to run experiments with different sales processes encouraging more reviews from customers about their purchases, such as by offering a small discount on future purchases.
Let's take a look at the volume of reviews by month to see if there are any trends or gaps we can look to exploit.
%%sql
-- Select brand, month from last_visited, and a count of all products in reviews aliased as num_reviews
-- Join traffic with reviews and brands on product_id
-- Group by brand and month, filtering out missing values for brand and month
-- Order the results by brand and month
SELECT
b.brand,
DATE_PART('month', t.last_visited) as month,
COUNT(r.product_id) as num_reviews
FROM traffic as t
INNER JOIN reviews as r
ON r.product_id = t.product_id
INNER JOIN brands as b
ON b.product_id = t.product_id
GROUP BY b.brand, month
HAVING b.brand is NOT NULL
AND DATE_PART('month', t.last_visited) is NOT NULL
ORDER BY b.brand, month
* postgresql://postgres:***@127.0.0.1/onlineretail
24 rows affected.
| brand | month | num_reviews |
|---|---|---|
| Adidas | 1.0 | 253 |
| Adidas | 2.0 | 272 |
| Adidas | 3.0 | 269 |
| Adidas | 4.0 | 180 |
| Adidas | 5.0 | 172 |
| Adidas | 6.0 | 159 |
| Adidas | 7.0 | 170 |
| Adidas | 8.0 | 189 |
| Adidas | 9.0 | 181 |
| Adidas | 10.0 | 192 |
| Adidas | 11.0 | 150 |
| Adidas | 12.0 | 190 |
| Nike | 1.0 | 52 |
| Nike | 2.0 | 52 |
| Nike | 3.0 | 55 |
| Nike | 4.0 | 42 |
| Nike | 5.0 | 41 |
| Nike | 6.0 | 43 |
| Nike | 7.0 | 37 |
| Nike | 8.0 | 29 |
| Nike | 9.0 | 28 |
| Nike | 10.0 | 47 |
| Nike | 11.0 | 38 |
| Nike | 12.0 | 35 |
8. Footwear product performance
Looks like product reviews are highest in the first quarter of the calendar year, so there is scope to run experiments aiming to increase the volume of reviews in the other nine months!
So far, we have been primarily analyzing Adidas vs Nike products. Now, let's switch our attention to the type of products being sold. As there are no labels for product type, we will create a Common Table Expression (CTE) that filters description for keywords, then use the results to find out how much of the company's stock consists of footwear products and the median revenue generated by these items.
%%sql
-- Create the footwear CTE, containing description and revenue
-- Filter footwear for products with a description containing %shoe%, %trainer, or %foot%
-- Also filter for products that are not missing values for description
-- Calculate the number of products and median revenue for footwear products
WITH footwear AS (
SELECT
i.description,
f.revenue
FROM info as i
INNER JOIN finance as f
ON f.product_id = i.product_id
WHERE (i.description ILIKE '%shoe%'
OR i.description ILIKE '%trainer%'
OR i.description ILIKE '%foot%') AND i.description IS NOT NULL
)
SELECT
COUNT(footwear.description) as num_footwear_products,
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY footwear.revenue) as median_footwear_revenue
FROM footwear
* postgresql://postgres:***@127.0.0.1/onlineretail
1 rows affected.
| num_footwear_products | median_footwear_revenue |
|---|---|
| 2700 | 3118.36 |
9. Clothing product performance
Recall from the first task that we found there are 3,117 products without missing values for description. Of those, 2,700 are footwear products, which accounts for around 85% of the company's stock. They also generate a median revenue of over $3000 dollars!
This is interesting, but we have no point of reference for whether footwear's median_revenue is good or bad compared to other products. So, for our final task, let's examine how this differs to clothing products. We will re-use footwear, adding a filter afterward to count the number of products and median_revenue of products that are not in footwear.
%%sql
-- Copy the footwear CTE from the previous task
-- Calculate the number of products in info and median revenue from finance
-- Inner join info with finance on product_id
-- Filter the selection for products with a description not in footwear
WITH footwear AS (
SELECT
i.description,
i.product_id,
f.revenue
FROM info as i
INNER JOIN finance as f
ON f.product_id = i.product_id
WHERE (i.description ILIKE '%shoe%'
OR i.description ILIKE '%trainer%'
OR i.description ILIKE '%foot%') AND i.description IS NOT NULL
)
SELECT
COUNT(i.product_id) as num_clothing_products,
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY f.revenue) as median_clothing_revenue
FROM info as i
INNER JOIN finance as f
ON f.product_id = i.product_id
--LEFT JOIN footwear
-- ON i.product_id = footwear.product_id
--WHERE i.description <> footwear.description
WHERE i.description NOT IN (SELECT description FROM footwear);
* postgresql://postgres:***@127.0.0.1/onlineretail
1 rows affected.
| num_clothing_products | median_clothing_revenue |
|---|---|
| 417 | 503.82 |