Harnessing Practical Ecommerce Data Scenarios with OpenAI API and ChromaDB Integration
Important applications for Ecommerce business also utilize textual data to either supplement other Machine Learning models with more data fields or can be used to quickly produce applications on their own and on the fly. Let’s have a quick look at those latter and how sole textual embeddings can quickly benefit Ecommerce businesses by ramping up quick AI application use cases. For this purpose lets employ three quick prototypes utilizing the OpenAI API and the ChromaDB vector database.
-
Semantic Search: Enhance search accuracy by understanding the meaning of search queries and product descriptions.
-
Product Recommendations: Use embeddings to suggest similar products based on user preferences and interactions.
-
Sentiment Analysis: Analyze product reviews and feedback sentiment at scale to understand customer satisfaction.
%load_ext dotenv
%dotenv
import os
OPENAI_TOKEN = os.environ.get("OPENAI_TOKEN")
print('')
The dotenv extension is already loaded. To reload it, use:
%reload_ext dotenv
from openai import OpenAI
import json
def prettyprint(input_dict):
return print(json.dumps(input_dict, indent=4))
1. Semantic search
(product search by the meaning of a search query text)
# Define a create_embeddings function
def create_embeddings(texts):
response = client.embeddings.create(
model="text-embedding-ada-002",
input=texts
)
response_dict = response.model_dump()
return [data['embedding'] for data in response_dict['data']]
# Define a function to combine the relevant features into a single string
def create_sample_product_text(product):
return f"""Title: {product['title']}
Description: {product['description']}
Category: {product['category']}
Subcategory: {product['subcategory']}
Features: {product['features']}"""
# Generate sample product data for home & garden retailers
import json
import random
# Generate fantasy brand names
def generate_fantasy_brand_names(num_names):
fantasy_brand_names = set()
prefixes = ["Aero", "Aqua", "Nova", "Vortex", "Frost", "Eclipse", "Celestial", "Serenity", "Mythic", "Zenith"]
suffixes = ["Tech", "Glo", "Luxe", "Co", "Works", "Innovations", "Industries", "Solutions", "Studios", "Designs"]
while len(fantasy_brand_names) < num_names:
brand_name = random.choice(prefixes) + random.choice(suffixes)
fantasy_brand_names.add(brand_name)
return list(fantasy_brand_names)
def generate_product_data(num_products):
product_data = []
product_names = set()
# Sample product categories and subcategories for home & garden
categories = ["Home Decor", "Furniture", "Kitchen & Dining", "Outdoor Living", "Tools & Home Improvement"]
subcategories = {
"Home Decor": ["Wall Art", "Throw Pillows", "Rugs", "Candles & Holders"],
"Furniture": ["Sofas & Couches", "Tables", "Chairs", "Bedroom Furniture"],
"Kitchen & Dining": ["Cookware", "Dinnerware", "Cutlery", "Appliances"],
"Outdoor Living": ["Patio Furniture", "Grills & Outdoor Cooking", "Outdoor Decor", "Gardening"],
"Tools & Home Improvement": ["Power Tools", "Hand Tools", "Lighting", "Storage & Organization"]
}
for i in range(num_products):
# Generate unique product name
product_name = ""
#while product_name in product_names:
category = random.choice(categories)
subcategory = random.choice(subcategories[category])
adjective = random.choice(["Premium", "Stylish", "Modern", "Classic", "Robust"])
noun = random.choice(["Sofa", "Table", "Chair", "Cookware Set", "Patio Furniture", "Power Drill"])
brand = generate_fantasy_brand_names(1)[0]
product_name = f"{brand} {adjective} {subcategory} {noun}"
product_names.add(product_name)
# Generate product description
description = " ".join([random.choice(["High-quality", "Durable", "Fashionable", "Functional", "Innovative"])
for _ in range(10)])
description += f" {random.choice(['This', 'That', 'The', 'A'])} {noun} is perfect for "
description += " ".join([random.choice(["everyday use", "enhancing your home decor", "outdoor entertaining",
"DIY projects"]) for _ in range(5)])
# Generate product features
features = {
"Material": random.choice(["Wood", "Metal", "Glass", "Plastic", "Stainless Steel"]),
"Color": random.choice(["White", "Black", "Gray", "Brown", "Blue", "Red"]),
"Size": random.choice(["Small", "Medium", "Large"]),
"Weight": round(random.uniform(5, 50), 2),
"Dimensions": f"{round(random.uniform(10, 200), 2)} x {round(random.uniform(10, 200), 2)} x {round(random.uniform(10, 200), 2)} cm"
}
# Generate other properties (e.g., price, category)
#price = round(random.uniform(20, 500), 2)
#category = category
# Store product data
product_data.append({
"title": product_name,
"description": description,
"category": category,
"subcategory": subcategory,
"features": features
})
return product_data
# Generate sample product data with 200 products
sample_product_data = generate_product_data(200)
# Save the sample product data as a dictionary
with open("sample_product_data_home_garden.json", "w") as file:
json.dump(sample_product_data, file)
print("Sample product data generated and saved.")
Sample product data generated and saved.
sample_product_data[0:2]
[{'title': 'VortexCo Robust Throw Pillows Table',
'description': 'Functional Innovative Fashionable Fashionable Durable Durable Fashionable Innovative Functional High-quality This Table is perfect for outdoor entertaining enhancing your home decor enhancing your home decor DIY projects everyday use',
'category': 'Home Decor',
'subcategory': 'Throw Pillows',
'features': {'Material': 'Glass',
'Color': 'Red',
'Size': 'Small',
'Weight': 48.16,
'Dimensions': '10.34 x 44.66 x 40.67 cm'}},
{'title': 'ZenithTech Classic Lighting Chair',
'description': 'Durable Functional Fashionable Innovative High-quality Durable Durable High-quality High-quality Durable A Chair is perfect for enhancing your home decor outdoor entertaining enhancing your home decor outdoor entertaining enhancing your home decor',
'category': 'Tools & Home Improvement',
'subcategory': 'Lighting',
'features': {'Material': 'Glass',
'Color': 'Black',
'Size': 'Large',
'Weight': 34.38,
'Dimensions': '68.98 x 55.57 x 133.89 cm'}}]
import scipy
def find_n_closest(query_vector, embeddings, n=3):
distances = []
for index, embedding in enumerate(embeddings):
# Calculate the cosine distance between the query vector and embedding
dist = scipy.spatial.distance.cosine(query_vector, embedding)
# Append the distance and index to distances
distances.append({"distance": dist, "index": index})
# Sort distances by the distance key
distances_sorted = sorted(distances, key=lambda x: x["distance"])
# Return the first n elements in distances_sorted
return distances_sorted[0:n]
import openai
# Set your API key
client = OpenAI(api_key = OPENAI_TOKEN)
# Load sample product data
with open("sample_product_data_home_garden.json", "r") as file:
sample_product_data = json.load(file)
# Combine the features for each product
product_texts = [create_sample_product_text(product) for product in sample_product_data]
# Create the embeddings from product_texts
product_embeddings = create_embeddings(product_texts)
# Create the query vector from query_text
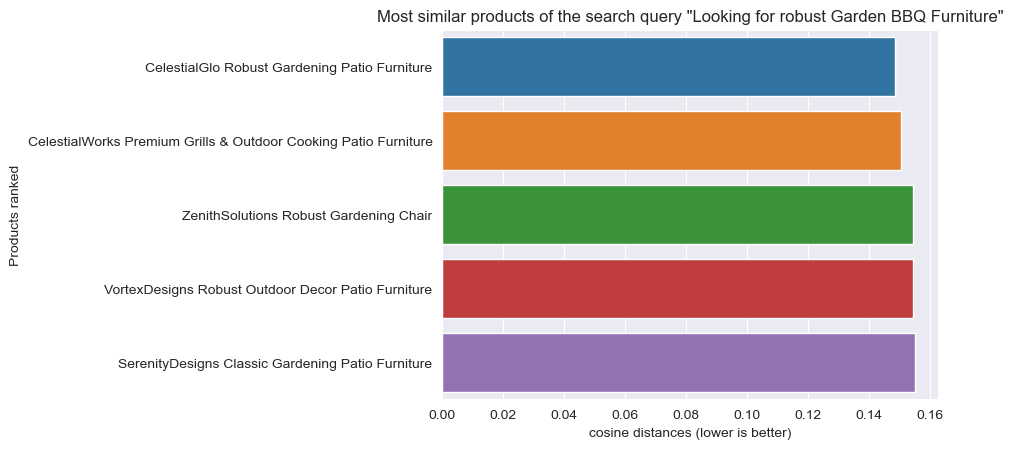
query_text = "Looking for robust Garden BBQ Furniture"
#query_text = "Looking for a stylish sofa to add elegance to my living room"
query_vector = create_embeddings(query_text)[0]
# Find the five closest distances
hits = find_n_closest(query_vector, product_embeddings, n=5)
hits
[{'distance': 0.14867675903741429, 'index': 68},
{'distance': 0.1506278676199394, 'index': 150},
{'distance': 0.15446661346349044, 'index': 16},
{'distance': 0.15472677219465913, 'index': 10},
{'distance': 0.1551121735884311, 'index': 112}]
print(f'Search results for query "{query_text}":\n')
for hit in hits:
# Extract the product at each index in hits
product = sample_product_data[hit['index']]
print(product["title"])
Search results for query "Looking for robust Garden BBQ Furniture":
CelestialGlo Robust Grills & Outdoor Cooking Sofa
ZenithCo Robust Grills & Outdoor Cooking Patio Furniture
SerenityGlo Robust Gardening Patio Furniture
AeroIndustries Robust Gardening Table
MythicCo Robust Gardening Sofa
import seaborn as sns
sns.set_style('darkgrid')
import matplotlib.pyplot as plt
distances = [item['distance'] for item in hits ]
titles = [sample_product_data[i]['title'] for i in [item['index'] for item in hits ]]
sns.barplot(y=titles, x=distances)
plt.xlabel('cosine distances (lower is better)')
plt.ylabel('Products ranked')
plt.title(f'Most similar products of the search query "{query_text}"')
plt.show()
2. Product recommendation system
(offer similar products for cross-/upsale by user product browsing history)
last_product = {'title': 'Building Blocks Deluxe Set',
'short_description': 'Unleash your creativity with this deluxe set of building blocks for endless fun.',
'price': 34.99,
'category': 'Toys',
'features': ['Includes 500+ colorful building blocks',
'Promotes STEM learning and creativity',
'Compatible with other major brick brands',
'Comes with a durable storage container',
'Ideal for children ages 3 and up']}
# Combine the features for last_product and each product in products
last_product_text = create_product_text(last_product)
product_texts = [create_product_text(product) for product in products]
# Embed last_product_text and product_texts
last_product_embeddings = create_embeddings(last_product_text)[0]
product_embeddings = create_embeddings(product_texts)
# Find the three smallest cosine distances and their indexes
hits = find_n_closest(last_product_embeddings, product_embeddings)
for hit in hits:
product = products[hit['index']]
print(product['title'])
Robot Building Kit
LEGO Space Shuttle
Luxury Perfume Gift Set
Adding user history to the recommendation engine
For many recommendation cases, such as film or purchase recommendation, basing the next recommendation on one data point will be insufficient. In these cases, you’ll need to embed all or some of the user’s history for more accurate and relevant recommendations.
user_history = [{'title': 'Remote-Controlled Dinosaur Toy',
'short_description': 'Roar into action with this remote-controlled dinosaur toy with lifelike movements.',
'price': 49.99,
'category': 'Toys',
'features': ['Realistic dinosaur sound effects',
'Walks and roars like a real dinosaur',
'Remote control included',
'Educational and entertaining']},
{'title': 'Building Blocks Deluxe Set',
'short_description': 'Unleash your creativity with this deluxe set of building blocks for endless fun.',
'price': 34.99,
'category': 'Toys',
'features': ['Includes 500+ colorful building blocks',
'Promotes STEM learning and creativity',
'Compatible with other major brick brands',
'Comes with a durable storage container',
'Ideal for children ages 3 and up']}]
import numpy as np
# Prepare and embed the user_history, and calculate the mean embeddings
history_texts = [create_product_text(product) for product in user_history]
history_embeddings = create_embeddings(history_texts)
mean_history_embeddings = np.mean(history_embeddings, axis=0)
# Filter products to remove any in user_history
products_filtered = [product for product in products if product not in user_history]
# Combine product features and embed the resulting texts
product_texts = [create_product_text(product) for product in products_filtered]
product_embeddings = create_embeddings(product_texts)
hits = find_n_closest(mean_history_embeddings, product_embeddings)
for hit in hits:
product = products_filtered[hit['index']]
print(product['title'])
Robot Building Kit
LEGO Space Shuttle
RC Racing Car
3. Sentiment Analysis
Embedding restaurant reviews for classification
sentiments = [{'label': 'Positive'},
{'label': 'Neutral'},
{'label': 'Negative'}]
reviews = ["The food was delicious!",
"The service was a bit slow but the food was good",
"Never going back!"]
# Create a list of class descriptions from the sentiment labels
class_descriptions = [topic['label'] for topic in sentiments]
# Embed the class_descriptions and reviews
class_embeddings = create_embeddings(class_descriptions)
review_embeddings = create_embeddings(reviews)
# Define a function to return the minimum distance and its index
def find_closest(query_vector, embeddings):
distances = []
for index, embedding in enumerate(embeddings):
dist = scipy.spatial.distance.cosine(query_vector, embedding)
distances.append({"distance": dist, "index": index})
return min(distances, key=lambda x: x["distance"])
for index, review in enumerate(reviews):
# Find the closest distance and its index using find_closest()
closest = find_closest(review_embeddings[index], class_embeddings)
# Subset sentiments using the index from closest
label = sentiments[closest['index']]['label']
print(f'"{review}" was classified as {label}')
"The food was delicious!" was classified as Positive
"The service was a bit slow but the food was good" was classified as Neutral
"Never going back!" was classified as Positive
The last review record was obviously misclassified as Positive. This shows how important context is and providing it is essential. Respinning with context:
sentiments = [{'label': 'Positive',
'description': 'A positive restaurant review'},
{'label': 'Neutral',
'description':'A neutral restaurant review'},
{'label': 'Negative',
'description': 'A negative restaurant review'}]
reviews = ["The food was delicious!",
"The service was a bit slow but the food was good",
"Never going back!"]
# Extract and embed the descriptions from sentiments
class_descriptions = [sentiment['description'] for sentiment in sentiments]
class_embeddings = create_embeddings(class_descriptions)
review_embeddings = create_embeddings(reviews)
def find_closest(query_vector, embeddings):
distances = []
for index, embedding in enumerate(embeddings):
dist = scipy.spatial.distance.cosine(query_vector, embedding)
distances.append({"distance": dist, "index": index})
return min(distances, key=lambda x: x["distance"])
for index, review in enumerate(reviews):
closest = find_closest(review_embeddings[index], class_embeddings)
label = sentiments[closest['index']]['label']
print(f'"{review}" was classified as {label}')
"The food was delicious!" was classified as Positive
"The service was a bit slow but the food was good" was classified as Neutral
"Never going back!" was classified as Negative
Scaling up data amount with the vector database Chromadb
limiting the scope to 1000 records in order to save on API costs
import chromadb
#import chromadb.utils.embedding_functions as OpenAIEmbedding
import chromadb.utils.embedding_functions as embedding_functions
client = chromadb.PersistentClient()
client.delete_collection("netflix_titles")
# Create a netflix_title collection using the OpenAI Embedding function
collection = client.create_collection(
name="netflix_titles",
embedding_function = embedding_functions.OpenAIEmbeddingFunction(api_key = OPENAI_TOKEN)
)
# List the collections
print(client.list_collections())
[Collection(name=netflix_titles)]
# importing DictReader class from csv module
from csv import DictReader
ids = []
documents = []
metas = []
with open('netflix_titles_1000.csv', encoding="utf8") as csvfile:
reader = DictReader(csvfile)
for i, row in enumerate(reader):
ids.append(row['show_id'])
text = f"Title: {row['title']} ({row['type']})\nDescription: {row['description']}\nCategories: {row['listed_in']}"
documents.append(text)
metatags = {'rating': row["rating"] , 'release_year': int(row["release_year"])}
metas.append(metatags)
"""{'ids': ['s999'],
'embeddings': None,
'metadatas': [{'rating': 'TV-14', 'release_year': 2021}],
'documents': ['Title: Searching For Sheela (Movie)\nDescription: Journalists and fans await Ma Anand Sheela as the infamous former Rajneesh commune’s spokesperson returns to India after decades for an interview tour.\nCategories: Documentaries, International Movies'],
'uris': None,
'data': None}"""
metas[0:2]
[{'rating': 'PG-13', 'release_year': 2020},
{'rating': 'TV-MA', 'release_year': 2021}]
prettyprint(metas[0:2])
[
{
"rating": "PG-13",
"release_year": 2020
},
{
"rating": "TV-MA",
"release_year": 2021
}
]
import tiktoken
# Load the encoder for the OpenAI text-embedding-ada-002 model
enc = tiktoken.encoding_for_model("text-embedding-ada-002")
# Encode each text in documents and calculate the total tokens
total_tokens = sum(len(enc.encode(text)) for text in documents)
cost_per_1k_tokens = 0.0001
# Display number of tokens and cost
print('Total tokens:', total_tokens)
print('Cost:', cost_per_1k_tokens * total_tokens/1000)
Total tokens: 51226
Cost: 0.005122600000000001
collection.add(ids=ids, documents=documents, metadatas=metas)
# Print the collection size and first ten items
print(f"No. of documents: {collection.count()}")
print(f"First ten documents: {collection.peek()}")
No. of documents: 1000
First ten documents: {'ids': ['s1', 's10', 's100', 's1000', 's101', 's102', 's103', 's104', 's105', 's106'], 'embeddings': [[-0.005216832738369703, 0.00743881706148386, -0.018072139471769333, -0.007921856828033924, -0.00598325626924634, 0.024976391345262527, -0.004737013019621372, -0.019012456759810448, -0.010008590295910835, -0.009937744587659836, 0.006788323167711496, 0.025556039065122604, -0.0008316339808516204, 0.013170892372727394, -0.014027483761310577, 0.0016278449911624193, 0.026483476161956787, 0.007516103330999613, 0.02952340804040432, -0.03557750955224037, 0.00026104290736839175, 0.01978532038629055, -0.007928297854959965, 0.021872054785490036, 0.022103913128376007, 0.013756981119513512, 0.0020013959147036076, -0.015534568578004837, 0.006343926303088665, 0.008501505479216576, 0.0030914563685655594, -0.009164880029857159, 0.006865609437227249, -0.05036497861146927, -0.008714042603969574, 0.00011079731484642252, -0.02815801464021206, -0.02422928996384144, 0.012958354316651821, -0.012333623133599758, -0.0006343926070258021, -5.2580922783818096e-05, -0.005622586235404015, -0.035448700189590454, -0.033336203545331955, 0.007908975705504417, 0.012121085077524185, -0.04894806072115898, 0.012327182106673717, 0.017647063359618187, 0.0222842488437891, 0.026084164157509804, -0.011444829404354095, -0.019141267985105515, 0.006595106795430183, -0.018664667382836342, 0.012398027814924717, 0.00371940853074193, 0.0058190226554870605, -0.0035648357588797808, 0.010040792636573315, -0.023005587980151176, -0.022838134318590164, -0.003993131220340729, -0.01253327913582325, -0.012082441709935665, -0.006884931121021509, -0.022374415770173073, 0.012488195672631264, 0.02694719471037388, 0.05054531246423721, 0.010510951280593872, 0.0042861755937337875, 0.018703311681747437, 0.01556033082306385, -0.00010445741645526141, -0.02332761511206627, 0.004627523943781853, 0.00047096406342461705, -0.003948047291487455, 0.014735941775143147, -0.01653929241001606, -0.019772440195083618, 0.025865186005830765, 0.0017421644879505038,
####### shortened ########
-0.0037990876007825136, -0.021795984357595444, 0.020235350355505943, 0.04393583908677101, -0.002274823607876897, 0.009674613364040852, -0.015593122690916061, -0.007333660963922739, -0.007677529472857714, 0.026054665446281433, -0.006080524064600468, -0.02342274785041809, 0.0005162163288332522, 0.0060739112086594105, 0.016690857708454132, -0.02055276744067669, -0.021385986357927322, 0.0029559482354670763, -0.02368726208806038, 0.008061075583100319, 0.0035444926470518112, -0.026517566293478012, -0.016360213980078697, 0.026200149208307266, 0.0008109018672257662, 0.022470496594905853, 0.01678343676030636, -0.013172815553843975, 0.014389581978321075, 0.02258952707052231, 0.016849566251039505, -0.002959254663437605, -0.0010489647975191474, -0.021716630086302757, -0.019534386694431305, 0.019521160051226616, 0.0022334931418299675, 0.012471852824091911, 0.005495286080986261, -0.007955269888043404, -0.026173697784543037, 0.042110688984394073, -0.03544492647051811, 0.05308803543448448, 0.005029079504311085, 0.0012986002257093787, 0.006682294420897961, -0.03168882057070732, -0.012061855755746365, 0.0003486216883175075, 0.007882528007030487, -0.02503628470003605, -0.008530588820576668, -0.007214629556983709, -0.00434464868158102, 0.011883308179676533, -0.024943705648183823, -0.03147720918059349, 0.021372761577367783, -0.028223684057593346, 0.016254408285021782, -0.010752509348094463, -0.013080235570669174, 0.009403485804796219, 0.0020681717433035374, 0.004466986283659935, 0.01284878607839346, -0.004900128580629826, -0.010897992178797722, 0.014230873435735703, 0.021280180662870407, -0.01538151130080223, -0.049913860857486725, -0.008173494599759579, -0.0005806917324662209, -0.019137615337967873, -0.024904027581214905, 0.01083847600966692, -0.02302597649395466, 0.019468257203698158, -0.0030353025067597628, -0.007439466658979654, 0.027377238497138023, -0.01315297745168209, 0.00813381653279066, -0.017034726217389107, -0.01205524243414402, 0.012809108942747116, -0.00354779907502234, -0.023965002968907356, -0.02141243778169155, -0.012987655587494373]], 'metadatas': [{'rating': 'PG-13', 'release_year': 2020}, {'rating': 'PG-13', 'release_year': 2021}, {'rating': 'TV-MA', 'release_year': 2021}, {'rating': 'TV-MA', 'release_year': 2021}, {'rating': 'TV-Y7', 'release_year': 2019}, {'rating': 'TV-MA', 'release_year': 2021}, {'rating': 'TV-14', 'release_year': 2021}, {'rating': 'TV-MA', 'release_year': 2020}, {'rating': 'TV-Y', 'release_year': 2016}, {'rating': 'TV-14', 'release_year': 2017}], 'documents': ['Title: Dick Johnson Is Dead (Movie)\nDescription: As her father nears the end of his life, filmmaker Kirsten Johnson stages his death in inventive and comical ways to help them both face the inevitable.\nCategories: Documentaries', "Title: The Starling (Movie)\nDescription: A woman adjusting to life after a loss contends with a feisty bird that's taken over her garden — and a husband who's struggling to find a way forward.\nCategories: Comedies, Dramas", 'Title: On the Verge (TV Show)\nDescription: Four women — a chef, a single mom, an heiress and a job seeker — dig into love and work, with a generous side of midlife crises, in pre-pandemic LA.\nCategories: TV Comedies, TV Dramas', 'Title: Stowaway (Movie)\nDescription: A three-person crew on a mission to Mars faces an impossible choice when an unplanned passenger jeopardizes the lives of everyone on board.\nCategories: Dramas, International Movies, Thrillers', "Title: Tobot Galaxy Detectives (TV Show)\nDescription: An intergalactic device transforms toy cars into robots: the Tobots! Working with friends to solve mysteries, they protect the world from evil.\nCategories: Kids' TV", 'Title: Untold: Breaking Point (Movie)\nDescription: Under pressure to continue a winning tradition in American tennis, Mardy Fish faced mental health challenges that changed his life on and off the court.\nCategories: Documentaries, Sports Movies', 'Title: Countdown: Inspiration4 Mission to Space (TV Show)\nDescription: From training to launch to landing, this all-access docuseries rides along with the Inspiration4 crew on the first all-civilian orbital space mission.\nCategories: Docuseries, Science & Nature TV', 'Title: Shadow Parties (Movie)\nDescription: A family faces destruction in a long-running conflict between communities that pits relatives against each other amid attacks and reprisals.\nCategories: Dramas, International Movies, Thrillers', "Title: Tayo the Little Bus (TV Show)\nDescription: As they learn their routes around the busy city, Tayo and his little bus friends discover new sights and go on exciting adventures every day.\nCategories: Kids' TV, Korean TV Shows", 'Title: Angamaly Diaries (Movie)\nDescription: After growing up amidst the gang wars of his hometown, Vincent forms an entrepreneurial squad of his own and ends up on the wrong side of the law.\nCategories: Action & Adventure, Comedies, Dramas'], 'uris': None, 'data': None}
Querying and updating the database
# Retrieve the netflix_titles collection
collection = client.get_collection(
name = "netflix_titles",
embedding_function = embedding_functions.OpenAIEmbeddingFunction(api_key = OPENAI_TOKEN)
)
# Query the collection for "films about dogs"
result = collection.query(query_texts=["series about business"], n_results=3)
prettyprint(result)
{
"ids": [
[
"s317",
"s48",
"s693"
]
],
"distances": [
[
0.3393472135066986,
0.34182170033454895,
0.3695303201675415
]
],
"metadatas": [
[
{
"rating": "TV-14",
"release_year": 2011
},
{
"rating": "TV-MA",
"release_year": 2020
},
{
"rating": "TV-14",
"release_year": 2021
}
]
],
"embeddings": null,
"documents": [
[
"Title: Office Girls (TV Show)\nDescription: A department store mogul has his son work incognito in a menial job to prove his worthiness, while female co-workers teach him how normal people live.\nCategories: International TV Shows, Romantic TV Shows, TV Comedies",
"Title: The Smart Money Woman (TV Show)\nDescription: Five glamorous millennials strive for success as they juggle careers, finances, love and friendships. Based on Arese Ugwu's 2016 best-selling novel.\nCategories: International TV Shows, Romantic TV Shows, TV Comedies",
"Title: The Rational Life (TV Show)\nDescription: A career-driven 30-something must contend with a cutthroat workplace, a love triangle and her nagging mom.\nCategories: International TV Shows, Romantic TV Shows, TV Dramas"
]
],
"uris": null,
"data": null
}
Querying with multiple texts
# Retrieve the netflix_titles collection
collection = client.get_collection(
name = "netflix_titles",
embedding_function = embedding_functions.OpenAIEmbeddingFunction(api_key = OPENAI_TOKEN)
)
reference_ids = ['s999', 's1000']
# Retrieve the documents for the reference_ids
reference_texts = collection.get(ids=reference_ids)["documents"]
# Query using reference_texts
result = collection.query( query_texts=reference_texts, n_results=3)
prettyprint(result['documents'])
[
[
"Title: Stowaway (Movie)\nDescription: A three-person crew on a mission to Mars faces an impossible choice when an unplanned passenger jeopardizes the lives of everyone on board.\nCategories: Dramas, International Movies, Thrillers",
"Title: Holiday on Mars (Movie)\nDescription: A scoundrel's mission to escape his family and remarry on Mars is hilariously scrubbed when a mishap with a black hole turns his son into an old man.\nCategories: Comedies, International Movies",
"Title: Planet 51 (Movie)\nDescription: After landing on a planet reminiscent of 1950s suburbia, a human astronaut tries to avoid capture, recover his spaceship and make it home safely.\nCategories: Children & Family Movies, Comedies, Sci-Fi & Fantasy"
],
[
"Title: Searching For Sheela (Movie)\nDescription: Journalists and fans await Ma Anand Sheela as the infamous former Rajneesh commune\u2019s spokesperson returns to India after decades for an interview tour.\nCategories: Documentaries, International Movies",
"Title: From Stress to Happiness (Movie)\nDescription: A stressed-out documentary filmmaker goes on a journey of discovery with a pair of monks, one of whom is known as \"the happiest man in the world.\"\nCategories: Documentaries, International Movies",
"Title: Ankahi Kahaniya (Movie)\nDescription: As big city life buzzes around them, lonely souls discover surprising sources of connection and companionship in three tales of love, loss and longing.\nCategories: Dramas, Independent Movies, International Movies"
]
]
# Retrieve the netflix_titles collection
collection = client.get_collection(
name="netflix_titles",
embedding_function = embedding_functions.OpenAIEmbeddingFunction(api_key = OPENAI_TOKEN)
)
reference_texts = ["children's story about a car", "lions"]
# Query two results using reference_texts
result = collection.query(
query_texts=reference_texts,
n_results=2,
# Filter for titles with a G rating released before 2019
where={
"$and": [
{"rating":
{"$eq": "G"}
},
{"release_year":
{"$lt": 2019}
}
]
}
)
prettyprint(result['documents'])
[
[
"Title: A Champion Heart (Movie)\nDescription: When a grieving teen must work off her debt to a ranch, she cares for a wounded horse that teaches her more about healing than she expected.\nCategories: Children & Family Movies, Dramas",
"Title: Hachi: A Dog's Tale (Movie)\nDescription: When his master dies, a loyal pooch named Hachiko keeps a vigil for more than a decade at the train station where he once greeted his owner every day.\nCategories: Children & Family Movies, Dramas"
],
[
"Title: A Champion Heart (Movie)\nDescription: When a grieving teen must work off her debt to a ranch, she cares for a wounded horse that teaches her more about healing than she expected.\nCategories: Children & Family Movies, Dramas",
"Title: Hachi: A Dog's Tale (Movie)\nDescription: When his master dies, a loyal pooch named Hachiko keeps a vigil for more than a decade at the train station where he once greeted his owner every day.\nCategories: Children & Family Movies, Dramas"
]
]
In the dynamic landscape of E-commerce applications, harnessing the power of metadata within databases is pivotal for enhancing user experiences. Imagine a scenario where product recommendations not only reflect users’ initial preferences but also refine results based on their individual settings. The ability to fine-tune recommendations through additional conditions demonstrates the true potential of leveraging metadata. To achieve this level of customization, cloud-based, managed vector databases such as Pinecone and Weaviate stand out as top contenders in this arena. Moreover, integrating such databases into a broader ecosystem, alongside large language models, is seamlessly facilitated by frameworks like LangChain, offering a unified syntax for comprehensive AI-driven solutions.
We quickly implemented three essential E-commerce applications with relatively few code and these prototypes could be measured and A/B tested against apps in place and their effectivness of enhancing user experience in search, better products recommended and for backoffice sentiment analysis purposes.